Bosworth-Toller's Anglo-Saxon Dictionary
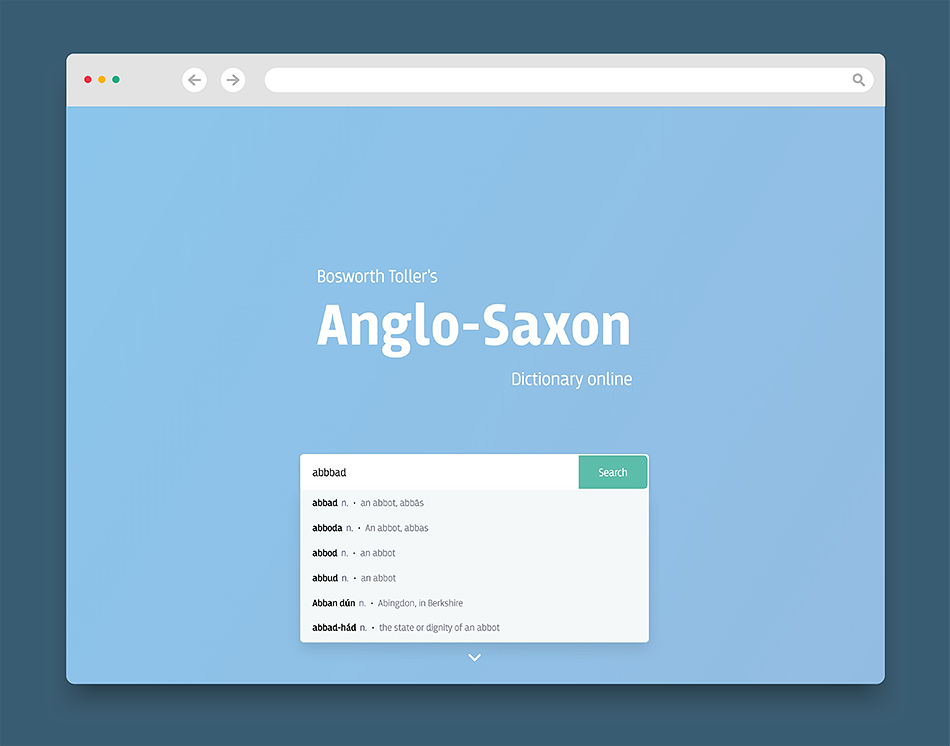
Představení
Bosworth-Tollerův Anglo-saský slovník je do dnešní doby největším slovníkem staré angličtiny. První edice tohoto slovníku vyšla již v roce 1838 a jejím autorem byl Joseph Bosworth. Tohmas Northcote Toller ji následně revidoval a od roku 1898 se díky tomu začal slovník označovat jako Bosworth-Tollerův. V roce 1921 navíc Thomas Northcote Toller vydal supplement se slovy a významny, které Bosworth opomněl. První digitální edici tohoto slovníku vytvořil Sean Christ v roce 2001 jakožto součást jeho projektu zaměřující se na germánské slovníky. V roce 2010 potom Ondřej Tichý z Filozofické fakulty Univerzity Karlovy využil data Sean Christa k vytvoření webového slovníku. Následně v roce 2013 jsme se s Ondřejem Tichým rozhodli, že bychom chtěli slovník modernizovat a přidat funkce, které stávající podoba neumožňovala.
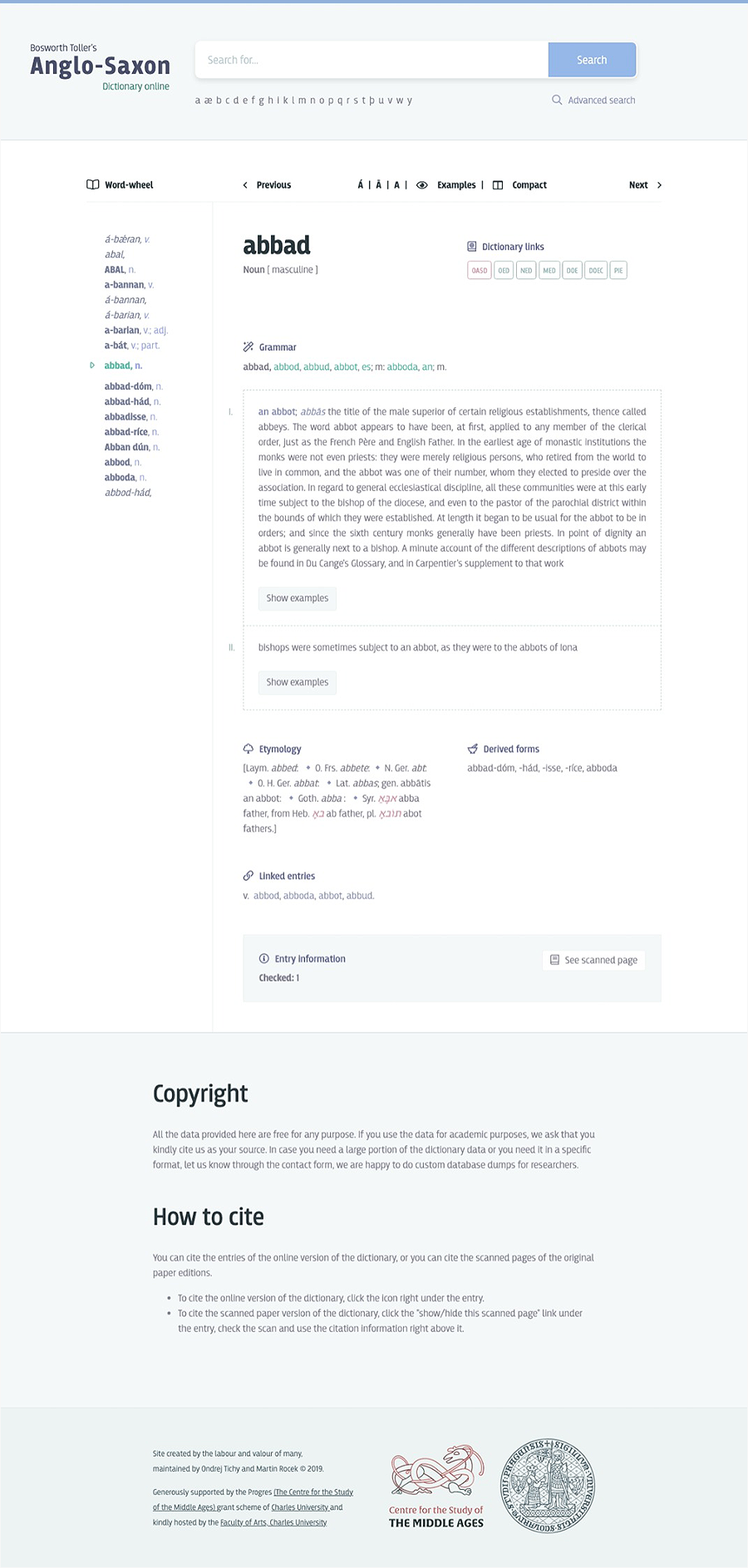 Stránka s heslem abbat v Bosworth-Tollerově slovníku
Stránka s heslem abbat v Bosworth-Tollerově slovníku
Zadání
Původní jádro slovníku bylo tvořeno CMS Drupal, které po drobných úpravách poskytovalo většinu funkcí. Nicméně s rozšířením mobilních telefonů přestalo stačit rozhraní, které bylo cílené především pro počítače. Zároveň Drupal pracoval pouze s HTML, které ve výsledku nebylo příliš vhodné k uchování struktury a podoby slovníku do budoucna. Hesla také obsahovala řadu OCR chyb, které by bylo vhodné odstranit. Já jsem byl poprošen, abych slovníku zpracoval nové čisté interface a navrhnul novou infrastrukturu, která by umožnila uchovávat data v XML podobě. Proces korekcí si vzal nastarost Ondřej Tichý, ten vzhledem k rozsahu slovníku probíhá do dnes.
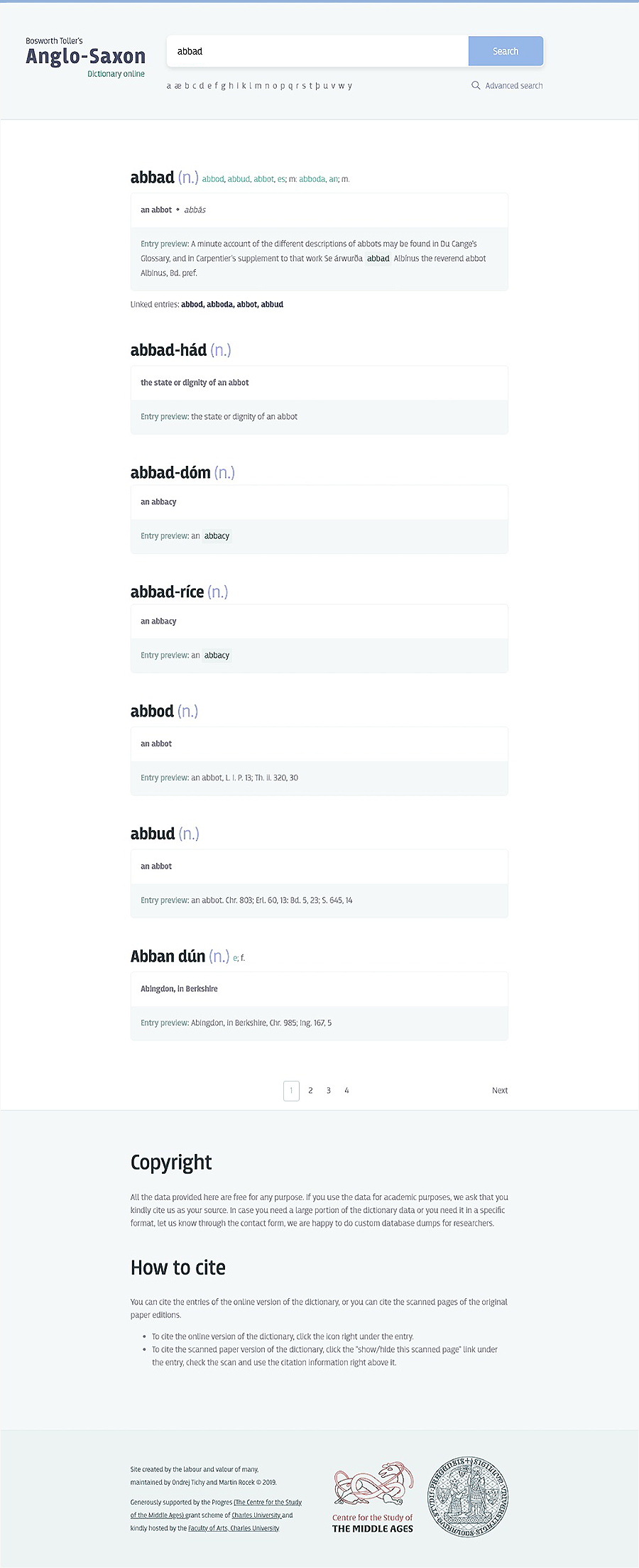 Klasické vyhledávání v Bosworth-Tollerově slovníku
Klasické vyhledávání v Bosworth-Tollerově slovníku
Řešení
Namísto spolehnutí se na existují CMS jsme se rozhodli postavit vlastní aplikaci s pomocí frameworku Laravel. Tím bylo dosaženo maximální kontroly nad zpracováním hesel a způsobu jejich následné distribuce do API a webového rozhraní. Přestože existuje řada XML databází bylo sáhnuto po klasické MySQL databázi, a to především proto, že poskytuje mnohem rychlejší odezvu. Nicméně díky tomu bylo nutné vyřešit jakým způsobem budou hesla ukládána v databázi. Nakonec jsme se rozhodli uchovávat nejen XML, ale dekonstruovat hesla do samostatných tabulek tak, aby bylo co nejlépe využito možností MySQL databáze. Nicméně stále před námi stála otázka ohledně vyhledávání, protože MySQL databáze neposkytuje příliš efektivní prostředí pro full-textové vyhledávání. Rozhodli jsme se tedy využít ElasticSearch engine. Tím bylo dosaženo mnohem efektivnějšího a spolehlivějšího vyhledávání než v původní aplikaci.
Uživatelské rozhraní bylo kompletně redesignováno. Namísto šedých barev, jež byly pro původní rozhraní typické bylo sáhnuto po živějším modro-zeleném schématu. Úvodní stránka byla zredukována na funkční minimum, neboť jejím hlavním účelem je poskytnout uživateli vyhledávání ve slovníku - to je také pro celou stránku dominantní. Po scrollování se zobrazí další informace, které byly předtím součástí úvodní stránky. O něco méně radikálně byla upravené stránka s informacemi o hesle, kde je nyní kladen větší důraz na logické sekce. Pro lepší orientaci byly přidány i ikonky, které také celý design zároveň oživují. Díky užití JavaScriptového frameworku Nuxt.js je také usnadněn vývoj a modifikace celé aplikace, neboť se skládá jen z několika mála samostatných komponent.
Celá aplikace je rozdělena do několika Docker kontejnerů, což v případě nutnosti umožňuje snadné škálování, případně A/B testování nových funkcí. Docker také usnadňuje aktualizaci, neboť vzhledem k oddělení jednotlivých služeb stačí aktualizovat pouze jeden daný kontejner.