Latin
Představení
Latin je slovník latinského jazyka. Jedná se především o studijní pomůcku, která má usnadnit hledání významů, či gramatických informací o latinských slovech. Na rozdíl od řady klasicky dostupných slovníků umožňuje vyhledávání pomocí tzv. regular expressions. Poradí si tak i ve chvíli, kdy si studenti či překladatel neví rady se slovem, protože není v původním listu zapsáno celé. Zároveň poněkud netradičně umožňuje vyhledávání několika slov najednou, neboť často můžeme hledat význam několika slov najednou. Dále také díky integraci několika dalších slovníkových databází značně zrychluje hledání slov a případných dalších významů, neboť nabízí přímé odkazy na další zdroje.
Zadání
Základem bylo vytvořit vyhledavač, který by umožnil vyhledávání několika latinských slov v reálném čase a nabídl informace o jejich gramatickém zařazení a případně i překlad. Výhodou by potom byl odkaz na další databáze, které se běžně používají. Vše mělo být jednoduché a snadno a rychle použitelné.
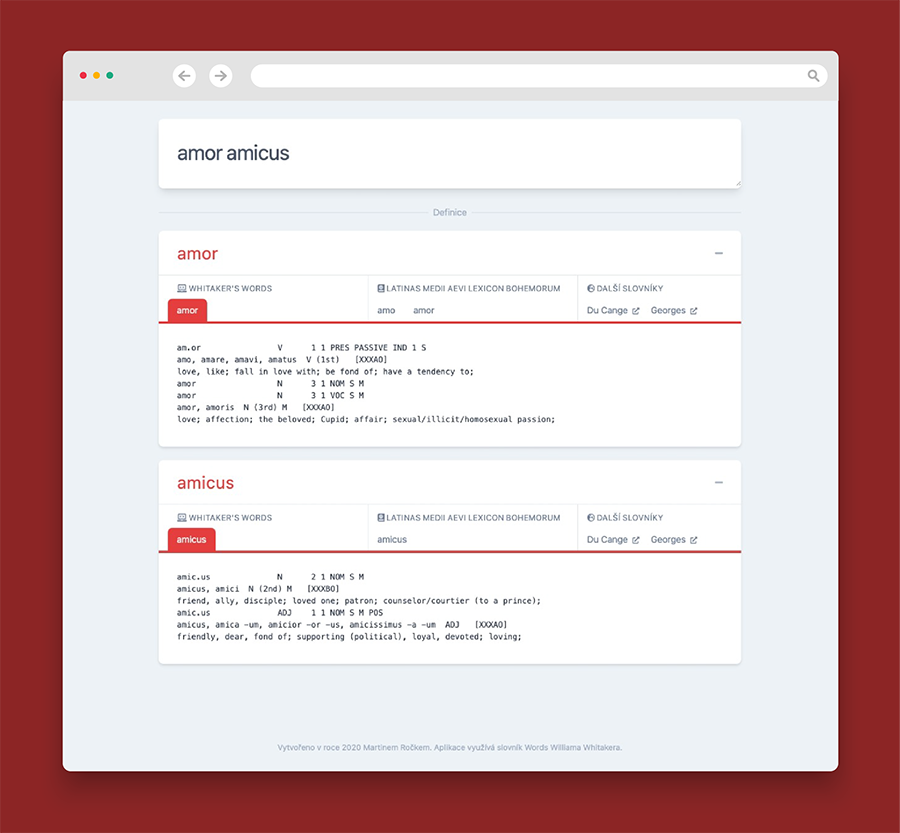
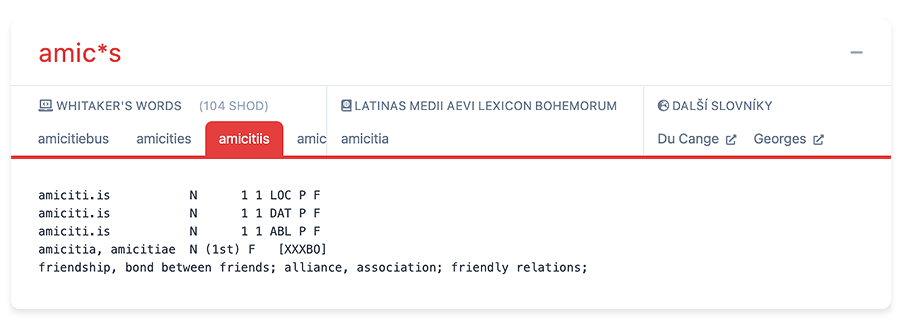 Box s gramatickými informacemi o slově
Box s gramatickými informacemi o slově
Řešení
Slovníková část aplikace se zakládá na analyzátoru Words Williama Whitakera, který je dnes volně dostupný na GitHubu. Díky tomu získala aplikace věrohodný zdroj dat gramatických informací a latinsko-anglických překladů. Nicméně, Words fungují pouze v příkazovém řádku, a tak bylo ještě nutné vyřešit jak by měla probíhat komunikace mezi uživatelem a serverem. K tomu posloužila jednoduchá Express.js aplikace, která odešle dotaz do Words a vrátí odpověď ve formě textového řetězce skrze API. Zároveň díky tomu, že Words obsahuje soubor se seznamem všech vygenerovaných slov, je v něm vyhledávat s pomocí regular expressions. Nalezené shody lze potom odeslat opět do Words a vrátit plnohodnotné výsledky. Tím byly splněny dvě základní podmínky pro Latin.
Napojení na zbývající slovníky bylo potom poměrně jednoduché, neboť většina jich neposkytuje žádné API a tudíž stačilo přidat několik odkazů. Výjimku v tomto případě tvoří Slovník středověké latiny v českých zemích, který má API s XML výstupem. Ten tedy bylo nutné s pomocí XSLT transformovat a následně přes API poskytnout front-endové části aplikace.